Over the past few days, I’ve been thinking about noSQL data structures. The thing with SQL is that it’s very codified, with clear expectations and standardized best practices. In contrast, the fluid nature of noSQL makes it hard to put your finger on exactly what you’re supposed to do.
Or how to think.
This, perhaps, is because noSQL is decentralized across multiple database providers — some cloud, self hosted, and open sourced. All of them have their own special requirements, methodologies with best practices. SQL doesn’t really have this problem as such. Once you’ve learned how relational databases work and how to talk to them, you’re covered for at least almost all the common things you need to do across different vendors.
Despite this, noSQL still has its perks — mostly in terms of solving a problem without the need to create a data interface between the application and the persistent data storage system.
Presenting…Firebase
Firebase is Google’s MVP friendly cloud database system that was acquired by the tech giant in 2014. Although it’s been around for a while, the hosted noSQL database has been flying mostly under the mainstream knowledge radar. Despite this, there were over 1.5 million apps using the service back in October 2018.
Firebase itself, however, is more than just a database. It’s a complete product with API interfaces, integrated auth platform, and associated cloud functions to leverage micro-service, back-end construction for things that need to be hidden on a server, such as payment processing.
When developing applications, you can’t really do much without a back end of sorts. Sure, you could just boot up your own back end and write your own API interfaces. However, if you’re new to the game or delving into unfamiliar territory, it could take anywhere between two weeks to several months to get a robust working solution. Then there’s the unknown bugs and quirks you’ve still got to encounter — taking you far from your original MVP goals.
The difference between using Firebase vs. creating your own back end is the difference between buying a box of Lego and building something from the provided blocks vs. creating each Lego piece from scratch and then doing something with it.
Let’s Talk About the Bill
Back in July 2018, a crowd funding campaign decided to use Firebase as their MVP’s back end. Everything was all good until they got hit with a $30,356.56 USD bill in 72 hours.
While the fault is on the side of the developers and not Firebase, the incident serves as a cautionary tale for many. However, it shouldn’t put you off from using Firebase in general. It’s a solid platform and can be a good solution for your MVP when put into balance against time and cost savings.
Everything you use will have a cost aspect to it. Unlike traditional cloud hosted database solutions, Firebase runs on a pay-per-use model. This billing model is in trend with the general shift away from the pay-per-hour model. There is a free tier for prototyping purposes, and, unless you’re hitting large amounts of traffic, there’s a high chance that you could run small applications on the platform for free.
It’s Not All That Bad
The perk of the pay-per-use model means that you’re not paying as much for storage but more on usage — a complete flip on how cloud based relational databases are billed.
With Amazon’s RDS, for example, you’re paying for an instance per hour — regardless of activity. The bigger your data storage requirements, the bigger your overall and guaranteed monthly bill will be. There is also an associated hard ceiling to the number of connections that can be made to the database as well.
In contrast, a pay-per-use model becomes elastic to your application’s consumption. For a Firebase database, this consumption is measured through the number of document read, writes, and deletes. Storage of data is a static price based on size of data stored. It’s also good to note that Firebase is a family of services packaged into one offering that includes file storage, hosting and cloud functions, among other things.
With the billing factor taken into consideration, it changes the way we think about data and our application’s relationship with it. Firebase, as a complete product, actually has two types of databases available for usage — cloud Firestore and Realtime Database. Both are noSQL databases, and higher conceptual thinking discussed here can be applied to both.
Thinking in noSQL With Firebase’s Firestore
noSQL itself is pretty open to however you want to structure. But with great flexibility comes the potential for great chaos. Data architecture and modelling is still required for future development sanity purposes.
Despite being technically schema-less, there is still an implicit schema for purposes of data consistency. The thing with SQL is that it runs on a single source of truth mentality. noSQL, however, advocates for data model and software development efficiency. The less processing, data joins, and filtering required, the better.
This can lead to data duplicates and the potential for inconsistent data if the developer is not aware of certain relationships. You could construct your noSQL data architecture to emulate relational tables — but that creates a potential billing problem. This is because when you call a set of documents from a collection, each document counts as one return.
Firebase’s Firestore runs on a collection → document structure. A collection is like a domain that groups a certain set of documents together — sort of like a table with each document being the entry.
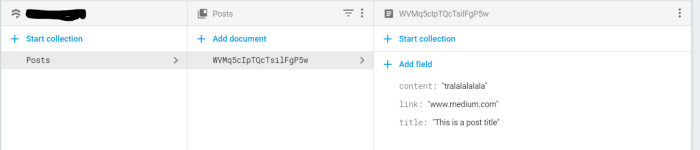
Let’s pretend that there are multiple documents in the data set above. If we wanted to create a page that listed ten posts on a particular page, it would result in ten document reads. If ten people visited the page, that’s 100 document reads. This number quickly scales up if you happen to viral and hit 100k in one day — resulting in 1,000,000 document reads for just a single page.
While the numbers may look somewhat frightening, it’ll only cost 60 cents on the Blaze plan.
In reality, you’ll probably end up with more than just ten posts, and the million document reads will increase proportionately — along with your final bill for just a single page. So how do you optimize it without creating chaos with duplicate data?
One method is to use composite mapping and aggregated documents.
Master Data and Aggregate Documents
SQL databases work off a single source of truth mentality. This single source of truth mentality can be applied to noSQL by abstracting data into relational styled collections and leveraging cloud functions to create aggregates.
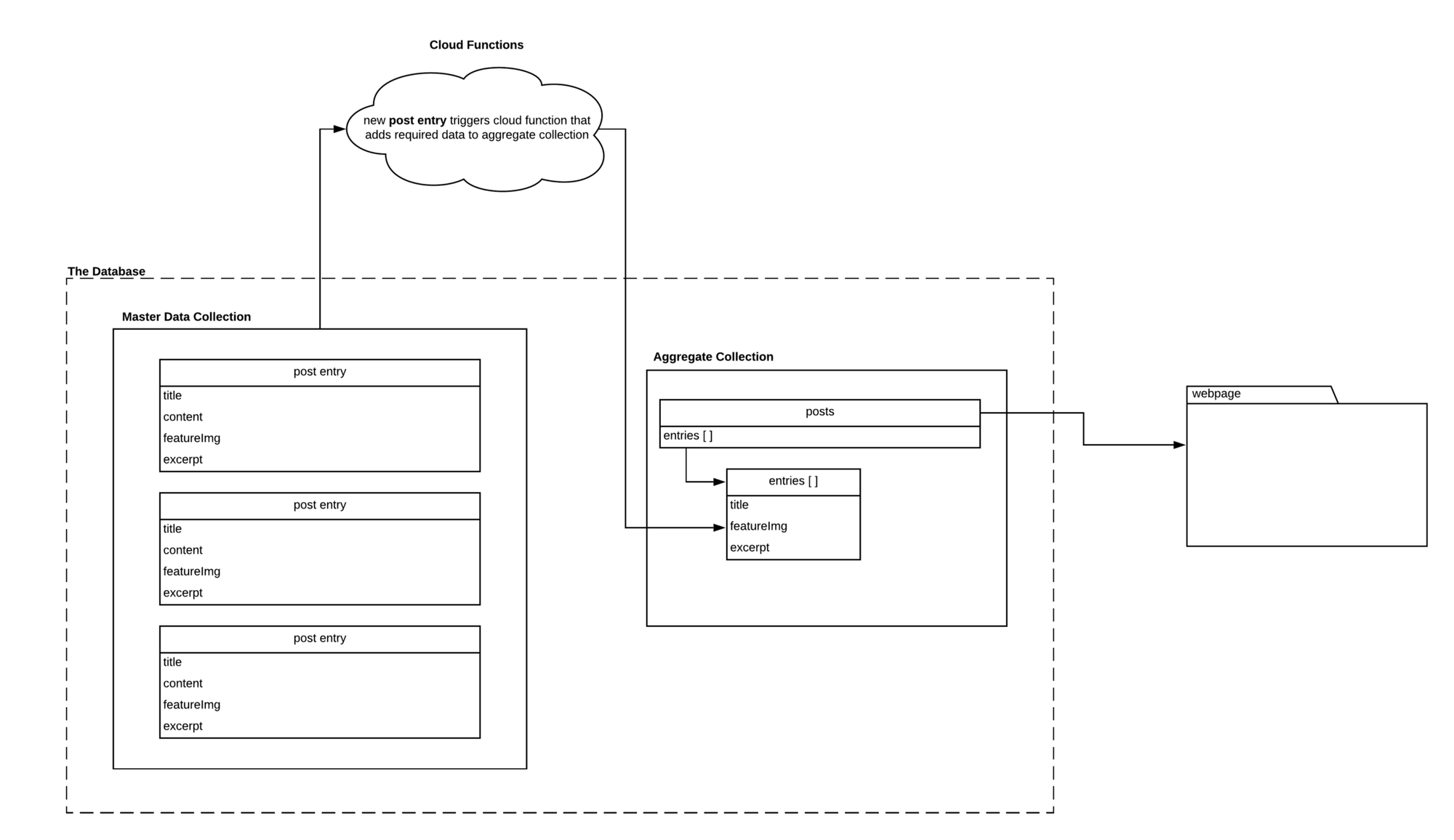
This structure works well for the potential final bill on scale and data integrity purposes. You write to the master collection and create cloud functions that trigger duplicate, but aggregated, documents with data models that you need for your front end’s consumption. Firebase encourages the usage of cloud functions, reflected in the pricing starting at per million calls.
While this increases the number of document writes you end up doing to your database, it’ll create savings through the massive reduction in total document reads. On balance, you’re going to end up with more document reads than writes — so it’s better to optimize for reads.
Having a master collection can help preserve your data’s integrity, as it can be used as a source of truth. This also means that if you need a specific view with certain aggregated data, you can use cloud functions to create the data model you want based on the data you already have.
Final Words
This is just one of many possible ways to look at noSQL data architecture in Firebase, and it is not prescriptive. Storing data is cheap in the noSQL world, so duplicates and aggregates aren’t as big of a deal as they are in SQL.
The best kind of data architecture is one that satisfies your immediate needs with the ability to pivot without breaking in major ways. Over abstraction is as bad as an unplanned database. The perk of noSQL is its fluidity but fluidity is also the database’s kryptonite when there’s no clear or enforced structure for larger and enterprise-sized data requirements.
For small applications with low traffic, you could get away with just creating collections and documents that contains data the way you need it. It won’t break your bank account. But it’s still good practice to get into the habit of thinking about data and how you might use it in the future.